Week 1 Lecture Notes
ML:Introduction
Where is machine learning used?

Introduction : where is machine learning used?
- web search engine like Google or Bing -> learned how to rank web pages
- Facebook or Apple's photo typing application -> recognizes your friends
- spam filter in your email
- web click data, also called clickstream data from Silicon Valley companies
moreover
- applications that can't be programmed by hand
- ex natural language processing
- handwriting recognition
- autonomous helicopter
https://www.computerworld.com/article/2542247/12-it-skills-that-employers-can-t-say-no-to.html
12 IT skills that employers can't say no to
Students with the right IT skills are getting snapped up before they graduate from college, job hunters say. But even if you're already in a career, you'd better know which adjunct skills will help you advance.
www.computerworld.com
A few months ago, a student showed me an article on the top twelve IT skills. The skills that information technology hiring managers cannot say no to. It was a slightly older article, but at the top of this list of the twelve most desirable IT skills was machine learning. Here at Stanford, the number of recruiters that contact me asking if I know any graduating machine learning students is far larger than the machine learning students we graduate each year. So I think there is a vast, unfulfilled demand for this skill set, and this is a great time to be learning about machine learning,

What is Machine Learning?
Two definitions of Machine Learning are offered. Arthur Samuel described it as: "the field of study that gives computers the ability to learn without being explicitly programmed." This is an older, informal definition.
Tom Mitchell provides a more modern definition: "A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P, if its performance at tasks in T, as measured by P, improves with experience E."
Example: playing checkers.
E = the experience of playing many games of checkers
T = the task of playing checkers.
P = the probability that the program will win the next game.
In general, any machine learning problem can be assigned to one of two broad classifications:
supervised learning, OR
unsupervised learning.









Supervised Learning
In supervised learning, we are given a data set and already know what our correct output should look like, having the idea that there is a relationship between the input and the output.
Supervised learning problems are categorized into "regression" and "classification" problems. In a regression problem, we are trying to predict results within a continuous output, meaning that we are trying to map input variables to some continuous function. In a classification problem, we are instead trying to predict results in a discrete output. In other words, we are trying to map input variables into discrete categories. Here is a description on Math is Fun on Continuous and Discrete Data.
Example 1:
Given data about the size of houses on the real estate market, try to predict their price. Price as a function of size is a continuous output, so this is a regression problem.
We could turn this example into a classification problem by instead making our output about whether the house "sells for more or less than the asking price." Here we are classifying the houses based on price into two discrete categories.
Example 2:
(a) Regression - Given a picture of Male/Female, We have to predict his/her age on the basis of given picture.
(b) Classification - Given a picture of Male/Female, We have to predict Whether He/She is of High school, College, Graduate age. Another Example for Classification - Banks have to decide whether or not to give a loan to someone on the basis of his credit history.





Unsupervised Learning
Unsupervised learning, on the other hand, allows us to approach problems with little or no idea what our results should look like. We can derive structure from data where we don't necessarily know the effect of the variables.
We can derive this structure by clustering the data based on relationships among the variables in the data.
With unsupervised learning there is no feedback based on the prediction results, i.e., there is no teacher to correct you.
Example:
Clustering: Take a collection of 1000 essays written on the US Economy, and find a way to automatically group these essays into a small number that are somehow similar or related by different variables, such as word frequency, sentence length, page count, and so on.
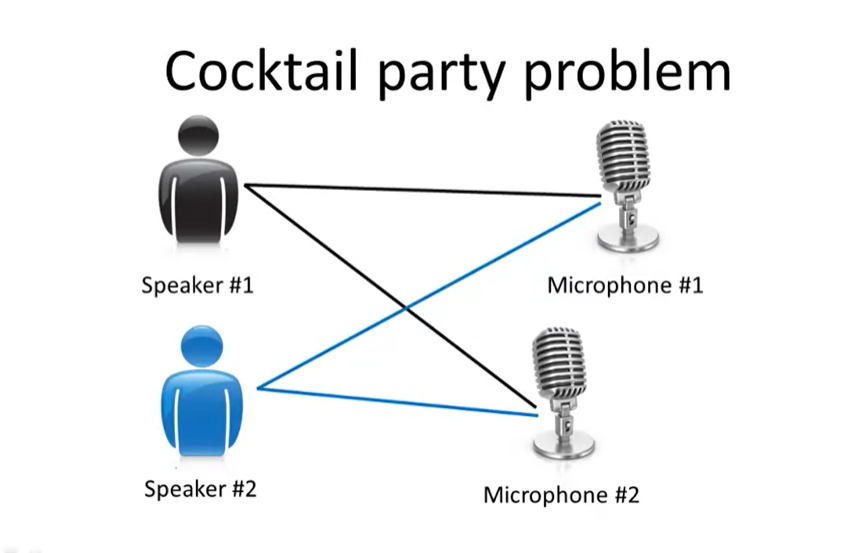
Non-clustering: The "Cocktail Party Algorithm", which can find structure in messy data (such as the identification of individual voices and music from a mesh of sounds at a cocktail party (https://en.wikipedia.org/wiki/Cocktail_party_effect) ). Here is an answer on Quora to enhance your understanding. : https://www.quora.com/What-is-the-difference-between-supervised-and-unsupervised-learning-algorithms ?





'머신러닝,딥러닝 > Andrew Ng 머신러닝 코세라 강의 노트' 카테고리의 다른 글
| Week 5 Lecture ML : Neural Net cost funcion (0) | 2020.10.24 |
|---|---|
| Week 4 Lecture ML : Neural Network (0) | 2020.08.10 |
| Week 3 Lecture ML : Classification and Representation (0) | 2020.08.07 |
| Week 2 lecture ML : quiz/ submitting lecture assignments (0) | 2020.08.07 |
| Week 2 Lecture ML : multiple features (0) | 2020.08.06 |
| Week 2 Lecture ML : Setting up Prog Env 'Octave' (0) | 2020.08.06 |
| Week 1 Lecture ML : Matrices and Vectors (0) | 2020.08.06 |
| Week 1 Lecture ML : Linear Regression ~ parameter learning (0) | 2020.08.06 |