




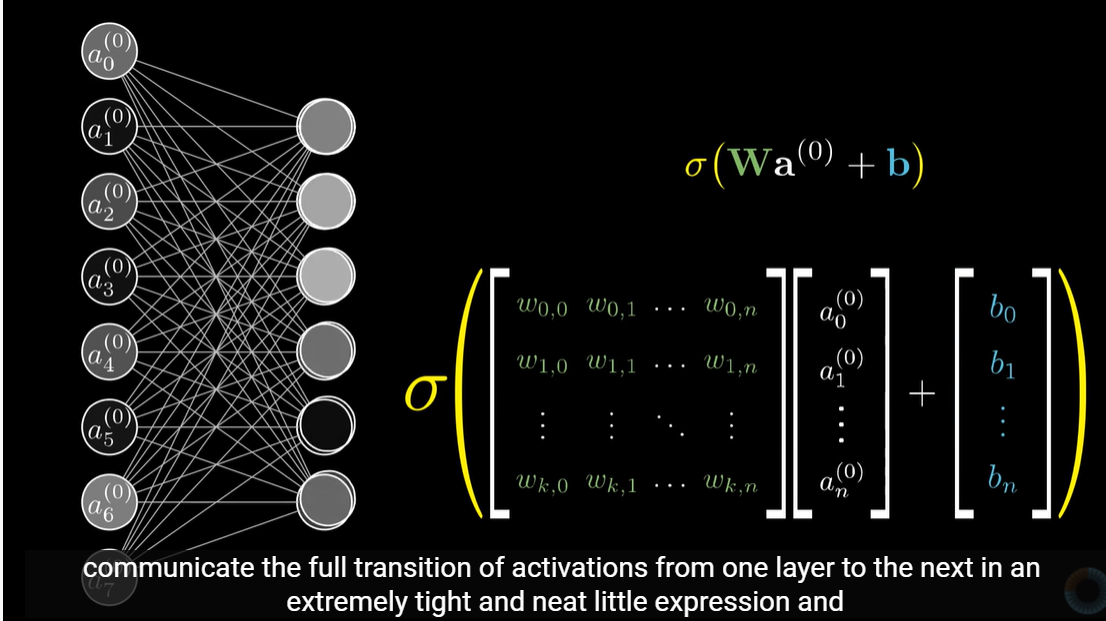
잘 만듬

Cost Function
Let's first define a few variables that we will need to use:
- L = total number of layers in the network
- s_l = number of units (not counting bias unit) in layer l
- K = number of output units/classes
Recall that in neural networks, we may have many output nodes. We denote h_\Theta(x)_k as being a hypothesis that results in the k^{th} output. Our cost function for neural networks is going to be a generalization of the one we used for logistic regression. Recall that the cost function for regularized logistic regression was:
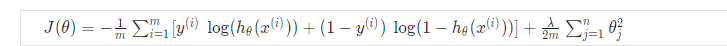
For neural networks, it is going to be slightly more complicated:

We have added a few nested summations to account for our multiple output nodes. In the first part of the equation, before the square brackets, we have an additional nested summation that loops through the number of output nodes.
In the regularization part, after the square brackets, we must account for multiple theta matrices. The number of columns in our current theta matrix is equal to the number of nodes in our current layer (including the bias unit). The number of rows in our current theta matrix is equal to the number of nodes in the next layer (excluding the bias unit). As before with logistic regression, we square every term.
Note:
- the double sum simply adds up the logistic regression costs calculated for each cell in the output layer
- the triple sum simply adds up the squares of all the individual Θs in the entire network.
- the i in the triple sum does not refer to training example i
https://www.youtube.com/watch?v=Ilg3gGewQ5U
'머신러닝,딥러닝 > Andrew Ng 머신러닝 코세라 강의 노트' 카테고리의 다른 글
| Week 4 Lecture ML : Neural Network (0) | 2020.08.10 |
|---|---|
| Week 3 Lecture ML : Classification and Representation (0) | 2020.08.07 |
| Week 2 lecture ML : quiz/ submitting lecture assignments (0) | 2020.08.07 |
| Week 2 Lecture ML : multiple features (0) | 2020.08.06 |
| Week 2 Lecture ML : Setting up Prog Env 'Octave' (0) | 2020.08.06 |
| Week 1 Lecture ML : Matrices and Vectors (0) | 2020.08.06 |
| Week 1 Lecture ML : Linear Regression ~ parameter learning (0) | 2020.08.06 |
| Week 1 Lecture ML:Intro ~ Supervised learning (0) | 2020.08.06 |