마찬가지로 주가 예측을 위한 딥러닝 모델에는 주가와 관련된 양질의 데이터 구조가 설계되어야 합니다. 이를 입력피쳐(입력특성) 설계라고 합니다.
성능이 좋은 모델을 만드려면 양질의 데이터와 특성이 입력해야 합니다. 예를 들어 컴퓨터에게 고양이가 무엇인지 가르쳐주려면 뾰족한 귀, 큰 눈, 삐쭉한 수염과 같은 고양이에 맞는 데이터와 특성을 가르쳐주어야겠죠.
이번 실습에서는 각각의 날짜의 중간값과 중간값의 5일 이동평균 데이터(MA(5))를 입력피쳐로 만들어 데이터에 추가해보도록 하겠습니다.
from datetime import datetime #날짜와 시간을 쉽게 조작할 수 있게 하는 클래스 제공
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
from sklearn.preprocessing import MinMaxScaler
from sklearn.preprocessing import StandardScaler
from tensorflow.keras import models
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dropout, Dense, Activation
from elice_utils import EliceUtils
#elice_utils = EliceUtils()
# 주식 데이터 불러오기
df = pd.read_csv('stock.csv')
#print('주식 데이터 확인하기')
#print(df)
# 주가의 중간값 계산하기
high_prices = df['High'].values # 고가
low_prices = df['Low'].values # 저가
mid_prices = (high_prices + low_prices) / 2 # 고가와 저가의 중간값
#print('주가의 중간값:', mid_prices)
# 주가 데이터에 중간 값 요소 추가하기
df['Mid'] = mid_prices # 'Mid' 열을 새로 만들고 mid_prices 데이터를 넣습니다.
#print(df)
# 종가의 이동평균값을 계산하고 및 주가 데이터에 추가합니다.
ma5 = df['Adj Close'].rolling(window=5).mean()
df['MA5'] = ma5 # 'MA5' 열을 새로 만들고 ma5 값을 넣습니다.
#df = df.fillna(0) # 비어있는 값을 모두 0으로 바꾸기
print(df)
주석 처리해봤는데 여기서 실제로 쓰는건
datetime이랑 pandas 뿐인듯 하다.

저번 강의처럼 주식데이터를 불러오는 read_csv함수를 사용하고

주가의 중간값들을 구하기 위해 df의 high열과 low열의 values를 가져와 평균을 구해준다.
그리고 MID 라는 열을 새로 추가하면 자동으로 append 된다

MID를 더하듯
MA5를 더하기 위해 rolling을 통해 평균값을 찾아 구하고 ma5변수에 넣어 추가한다
rolling함수의 window는 몇개를 연산할 지
mean() : 평균내기

함수를 모르면 직접 구현하는 수 밖에

df = df.fillna(0)은 NaN을 0으로 바꿔주는 것
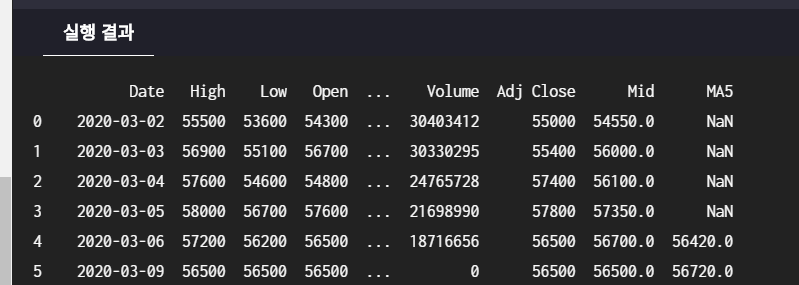
이전에는 NaN이라면

실행후에는 0.0으로 대체되어 있다
데이터 전처리란 효과적인 데이터 분석 및 예측을 위해 입력되는 데이터의 형태 등을 다듬는 것을 말합니다.
from datetime import datetime #날짜와 시간을 쉽게 조작할 수 있게 하는 클래스 제공
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
from sklearn.preprocessing import MinMaxScaler
from sklearn.preprocessing import StandardScaler
from tensorflow.keras import models
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dropout, Dense, Activation
from elice_utils import EliceUtils
pd.set_option('display.max_columns', None)
elice_utils = EliceUtils()
# --- 주식 데이터 불러오기(이전 실습에서 진행) --- #
df = pd.read_csv('stock.csv')
# 주가의 중간값 계산하기
high_prices = df['High'].values # 고가
low_prices = df['Low'].values # 저가
mid_prices = (high_prices + low_prices) / 2 # 고가와 저가의 중간값
# 주가 데이터에 중간 값 요소 추가하기
df['Mid'] = mid_prices # df.insert() 대신 이와 같이 사용 가능합니다.
#이동평균값 계산 및 주가 데이터에 추가하기
ma5 = df['Adj Close'].rolling(window=5).mean()
df['MA5'] = ma5
df = df.fillna(0) # 비어있는 값을 모두 0으로 바꾸기
print('전처리 전의 주가 데이터')
print(df)
# --- 데이터 전처리 --- #
# Date 열을 제거합니다.
df = df.drop('Date', axis = 1)
# 데이터 스케일링(MinMaxScaler 적용)
min_max_scaler = MinMaxScaler()
fitted = min_max_scaler.fit(df)
output = min_max_scaler.transform(df)
output = pd.DataFrame(output, columns=df.columns, index=list(df.index.values))
print('\n전처리 후의 주가 데이터')
print(output.head())
인공지능을 사용할 때 데이터의 전처리는 가장 중요한 요소 중 하나입니다. 데이터의 값이 너무 크거나 작으면 제대로 반영되지 않으며, 알고리즘의 계산 과정에서 결과값이 0으로 수렴하거나 값이 너무 커져버리거나 할 수 있기 때문입니다.
데이터 전처리에는 수많은 방법이 있지만, 이번 실습에서는 그 중 하나인 데이터 스케일링를 실행해보도록 하겠습니다.
예컨대 우리가 입력한 데이터 중 첫 번째 특성은 데이터의 범위가 1~8이지만, 두 번째 특성은 데이터의 범위가 3000-3300이라고 생각해봅시다. 절대적인 크기 변화 자체는 매우 크기 때문에 기계가 두 번째 특성의 변화폭이 더 크다고 오해할 수 있습니다. 이런 문제를 해결하기 위해 각 데이터 열의 데이터의 범위를 맞추어주는 작업을 데이터 스케일링이라고 합니다.
- Min-Max Scaler(최소-최대 스케일러):
각 열의 데이터 중 최소값이 0, 최대값이 1이 되도록 하여, 해당 열의 모든 데이터가 0-1사이에 위치하도록 범위를 조정합니다.

이전 실습에서 한 내용

드디어 라이브러리 하나 사용!
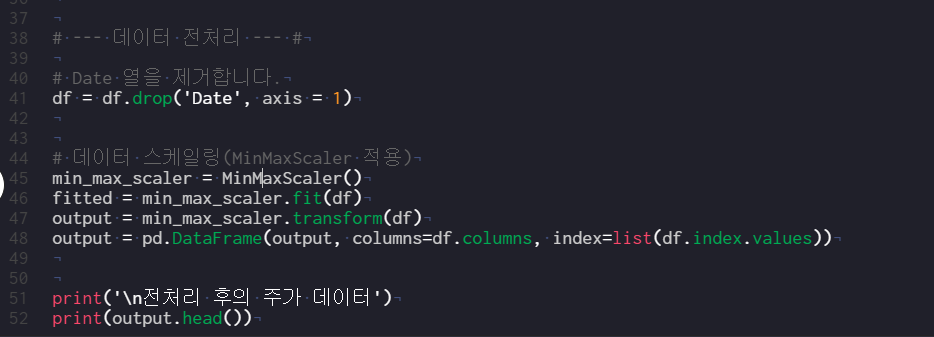
여기가 데이터 전처리 부분
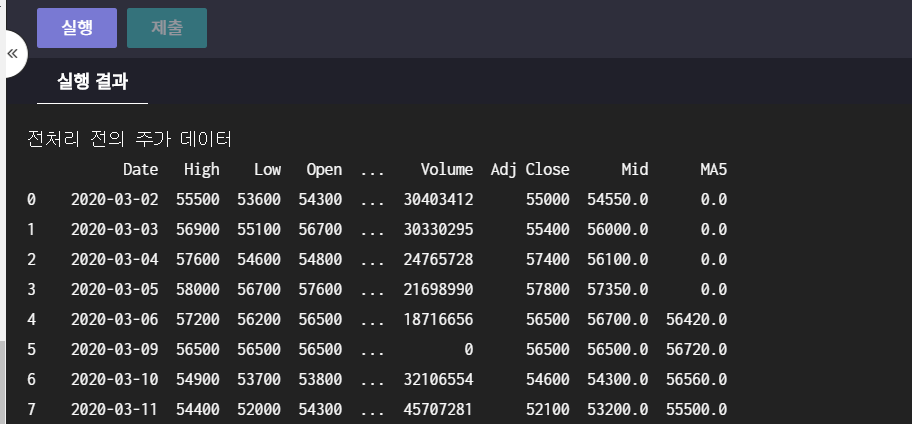
우선 전처리를 하기 전의 결과
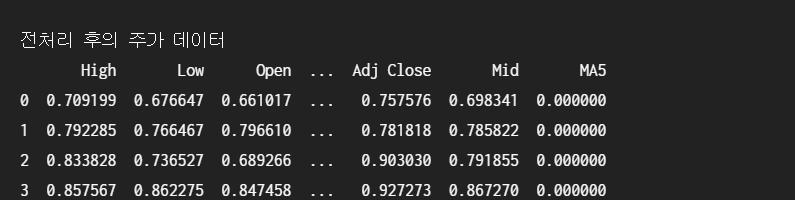
전처리를 한 결과 .
일단 보면 Date, Volume 등의 열이 아예 통째로 사라졌고
high low open 등의 값이 0~1 사이 값이 되었다!!

우선 drop을 통해 Date열을 통째로 제거해줬고 (?) volume은???

min_max_sclaer로 MinMaxScaler()을 변수에 넣었다.
fitted = MinMaxScelr().fit(df)등으로 고쳐봐도 안됨

만약 fitted을 주석처리하면 transform하기에 아직 fit하지 않았다고 써있다.
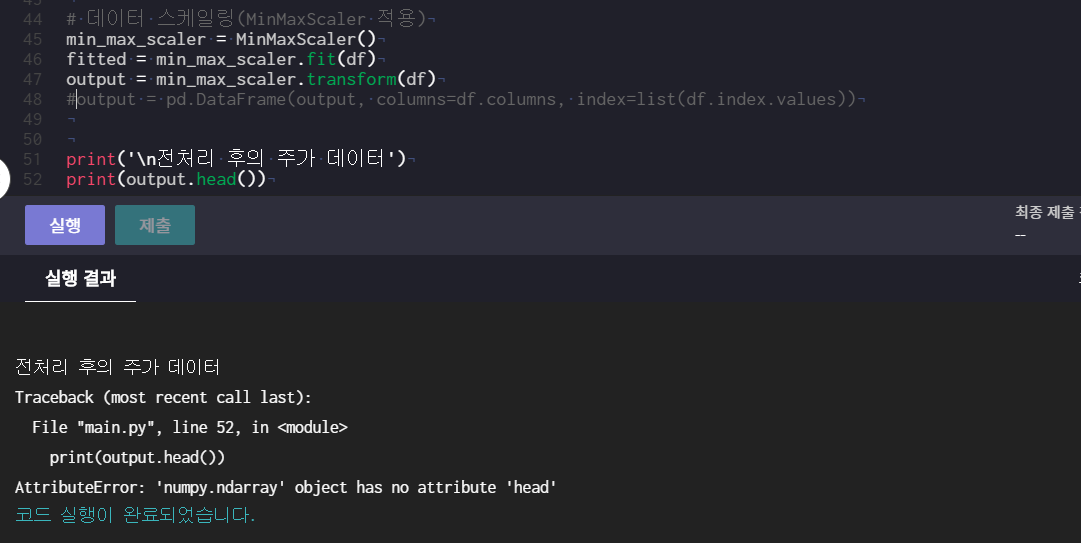
ouput을 주석처리하면 output.head()하기에 atrribute가 없다는 에러가 뜬다.
만들어진 ouput을 DataFrame화 해야 하나 보다.

만약 그냥 transform한 상태에서 output을 프린트하게 되면 list형식으로 주루룩 나열되어 있는 숫자들을 볼 수 있다.
자세히 살펴보면 ouput[0]은 0번 행의 high low volume ma5등 이 차례대로 있는 상태의 리스트다!
ouput = pd.dataframe(~~~)은 df가 프린트되듯 예쁘게 엑셀 형태로 프린트되기 위한 함수임을 확인할 수 있다.

Dataframe 함수 관한 설명 찾아보니 이렇게 생긴 리스트를 표화 해주는 거였다!
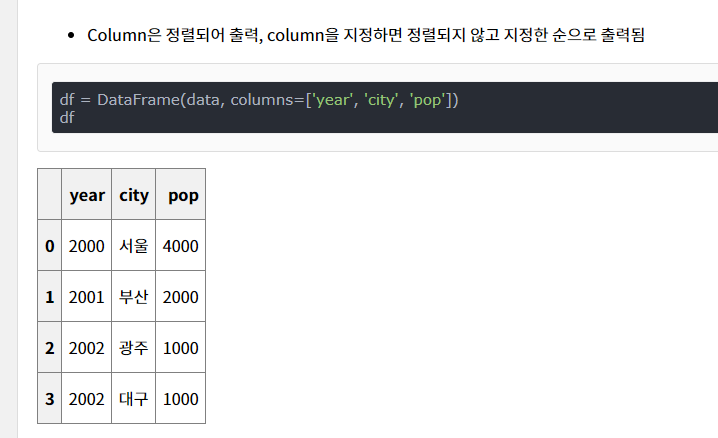
columns = 매개변수는 위의 열이름을 설정!

index = 매개변수는 옆의 행 이름을 설정

48번줄을 다시 해석해보면 ouput이라는 그냥 이중리스트를, df의 칼럼을 그대로 인용하고 index는 df의 인덱스 값의 리스트에서 그대로 가져온다 (0 1 2 3 4.. )
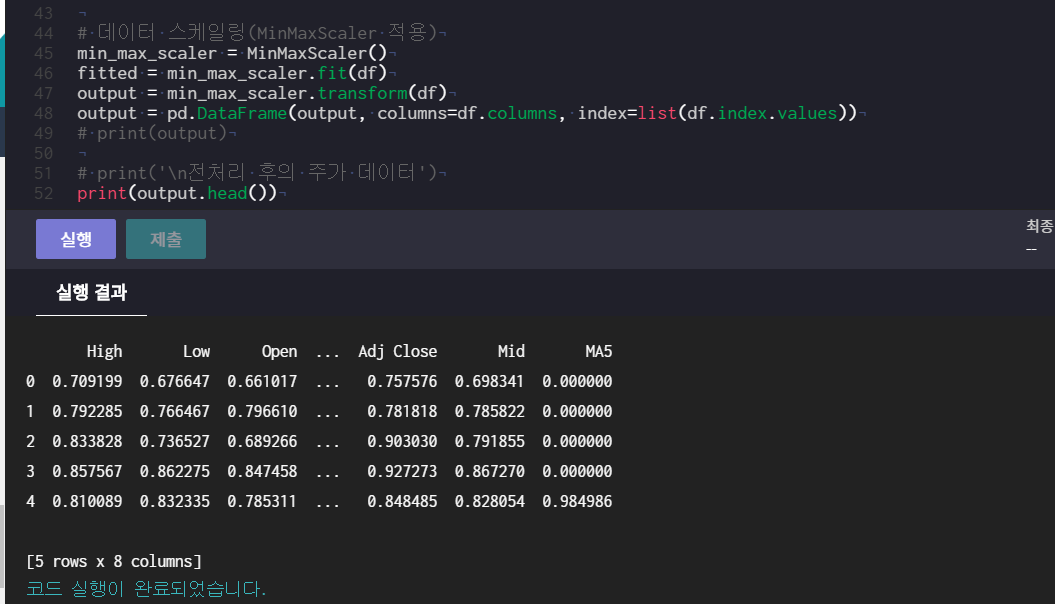
print(output)과 다르게 print(output.head())은 상위 5개만 쏙 빼온다! 이것도 tail과 함께 같이 배웠지.
데이터셋 분리하기
from datetime import datetime #날짜와 시간을 쉽게 조작할 수 있게 하는 클래스 제공
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
from sklearn.preprocessing import MinMaxScaler
from sklearn.preprocessing import StandardScaler
from tensorflow.keras import models
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dropout, Dense, Activation
from elice_utils import EliceUtils
elice_utils = EliceUtils()
# --- 주식 데이터 불러오고 전처리하기(이전 실습에서 진행) --- #
df = pd.read_csv('stock.csv')
# 주가의 중간값 계산하기
high_prices = df['High'].values
low_prices = df['Low'].values
mid_prices = (high_prices + low_prices) / 2
# 주가 데이터에 중간 값 요소 추가하기
df['Mid'] = mid_prices
# 종가의 5일 이동평균값을 계산하고 주가 데이터에 추가하기
ma5 = df['Adj Close'].rolling(window=5).mean()
df['MA5'] = ma5
df = df.fillna(0) # 비어있는 값을 모두 0으로 바꾸기
# Date 열를 제거합니다.
df = df.drop('Date', axis = 1)
# 데이터 스케일링(MinMaxScaler 적용)
min_max_scaler = MinMaxScaler()
fitted = min_max_scaler.fit(df)
output = min_max_scaler.transform(df)
output = pd.DataFrame(output, columns=df.columns, index=list(df.index.values))
# --- 데이터셋 나누기 --- #
# 0~60% 지점까지를 트레인셋(학습 데이터)으로 설정(전체의 60%)
train_size = int(len(output)* 0.6)
# 60-90% 지점까지를 테스트셋으로 설정(전체의 30%)
test_size = int(len(output)*0.3) + train_size
#train/test 학습 및 라벨 설정
#종가를 예측하기 위해 종가를 label로 설정
train_x = np.array(output[:train_size]) # 트레인셋의 독립변수
train_y = np.array(output['Close'][:train_size]) # 트레인셋의 종속변수
test_x =np.array(output[train_size:test_size]) # 테스트셋의 독립변수
test_y = np.array(output['Close'][train_size:test_size]) # 테스트셋의 종속변수
validation_x = np.array(output[test_size:]) # 트레인셋의 독립변수
validation_y = np.array(output['Close'][test_size:]) # 테스트셋의 종속변수
print('분할 전 전체 데이터의 길이: %s' % len(output))
print('학습 데이터의 길이: %s' % len(train_x))
print('테스트 데이터의 길이: %s' % len(test_x))
print('검증용 데이터의 길이: %s' % len(validation_x))
충분한 데이터를 구할 수 없을 경우, 효과적인 예측을 위해 데이터셋을 분할한 후 학습을 진행시켜야 합니다. 예를 들어 전체 데이터를 50:50으로 A와 B로 랜덤하게 나누어본다고 생각해봅시다. 그리고 전체 데이터 중 A 데이터로만 딥러닝 모델을 학습을 시킵니다. B 데이터는 전혀 사용되지 않았으므로, 이 모델은 B에 대한 아무런 정보도 가지고 있지 않습니다. 그런 다음 우리는 이 모델을 가지고 B 범위에 있는 데이터를 예측해봅니다. 만약 우리가 성공적으로 딥러닝 모델을 학습시켰다면, 이 예측 값들은 B 데이터와 비슷하게 나타날 것입니다. 반대로 모델 학습이 제대로 이루어지지 않았다면 B 데이터에 대한 예측 결과는 형편없겠죠. 이와 같이 데이터를 학습/테스트 용도로 나누는 것을 데이터셋 분할(split) 이라고 합니다.
독립변수와 종속변수
인공지능은 대개 일반적인 정보만을 활용하여 특정한 목표값을 예측하기 위해 사용합니다. 이 때 일반적인 정보들을 독립변수, 목표값을 종속변수라고 합니다.
예컨대 아파트의 위치, 층수, 연식, 한강뷰 여부, 브랜드 등의 정보들을 가지고 매매가를 예측한다고 생각해봅시다. 이 때 입력된 위치, 층수, 연식 등의 데이터가 독립변수, 목표값인 집값이 종속변수가 됩니다.
목표값(정답)이 있는 훈련 데이터들을 이용하여 임의의 데이터로부터 예측하고자 하는 값을 올바르게 추측해내는 함수를 학습하는 방법을 지도학습(Supervised Learning)이라고 합니다.

자 41번까지는 저번 시간에 배운 데이터 전처리 과정 내용이다.

여기가 데이터셋나누기.

첫 부분은 지점까지 트레인셋=학습데이터를 설정하는 코드다.
output의 길이 105를 0.6을 곱해 60%의 수를 찾고 소수점이라면 제거를 위해 int를 둘러싼다.
참고로 만약 int를 둘러싸지 않는다면 63.0 처럼 실제 정수여도

뒤의 코드가 float는 싫다며 에러를 띄운다
int를 둘러싸야 이후 pandas함수를 쓸 때 에러가 없다.

다음 부분은 train/test학습 라벨 설정 내용이다.
train_x와 train_y를 직접 프린트하면 저번 minmax로 transform한 output처럼 숫자가 나열되어 있는 리스트만 출력된다
여기 코드는 numpy를 npㄹ고 줄여써서 np.array라고만 썼는데 사실 numpy.array이다
만약 여기서 as로 줄인다면 긴 라이브러리 명을 간단하게 쓸 수 있다

numpy에 대한 간단한 설명이다. numpy는 배열연산이 최적화되어 있어 이러한 배열을 자르고 붙이는데 쓰는 것 같다
다시 돌아가서 train_x의 경우 ouput배열을 60% 인덱스 지점까지 자르는 것 같고

train_y는 ouput중에서도 close열의 60%지점까지 자르는 것 같다 (train_y는 일차원 배열)

train_x랑 train_y 처럼
test_x랑 test_y 도 똑같이 numpy.array(output~이지만 다만 다른 점은 60~90지점까지 자른다는 점이다.
이때 다시 명심할 점은 train_size는 아까 계산했던 int형 숫자다

validataion_x 와 validation_y도 마찬가지다
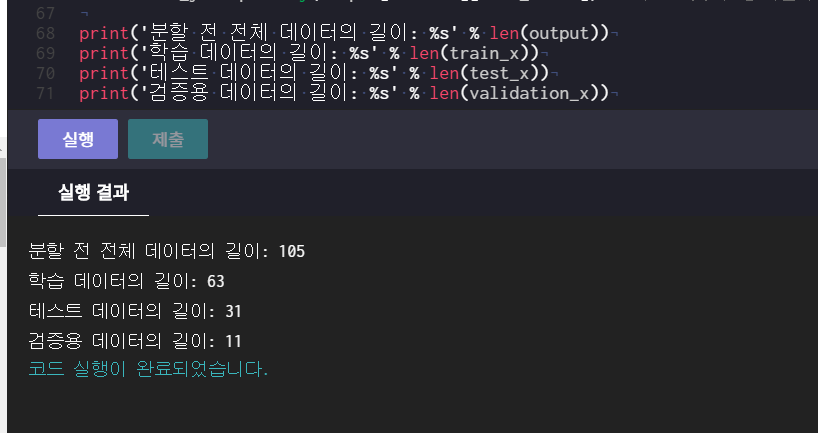
그 결과 데이터셋을 분할하는데 성공했다 train_x test_x validatoin_x모두 배열 형태고
numpy.array에 의해 output이라는 105짜리 배열을 각각 63, 31, 11로 나누어진 것이다.
긴 표를 조금씩 잘라 새로운 변수에 넣었다고 생각하면 편할 것 같다
keras를 이용한 딥러닝 수행
지금까지 우리는 주식 데이터 전처리를 진행해왔습니다. 이제 드디어 이 데이터와 Keras라는 라이브러리로 딥러닝 모델 학습을 진행해보도록 하겠습니다.
Keras는 최근 가장 많이 사용되는 딥러닝 라이브러리 중 하나로 딥러닝을 구현하는데 필요한 많은 함수와 기능들을 가지고 있습니다.

케라스를 쓰는 이유에 대해 써져 있는데 결론은 딥러닝을 표현하는데 굉장히 쉬운 라이브러릴라고 한다
from datetime import datetime
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
from sklearn.preprocessing import MinMaxScaler
from sklearn.preprocessing import StandardScaler
from tensorflow.keras import models # Keras 라이브러리를 불러옵니다
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dropout, Dense, Activation
from elice_utils import EliceUtils
elice_utils = EliceUtils()
# --- 주식 데이터 로드, 전처리, 분할하기(이전 실습에서 진행) --- #
df = pd.read_csv('stock.csv')
# 주가의 중간값 계산하기
high_prices = df['High'].values
low_prices = df['Low'].values
mid_prices = (high_prices + low_prices) / 2
# 주가 데이터에 중간 값 요소 추가하기
df['Mid'] = mid_prices
# 종가의 5일 이동평균값을 계산하고 주가 데이터에 추가하기
ma5 = df['Adj Close'].rolling(window=5).mean()
df['MA5'] = ma5
df = df.fillna(0) # 비어있는 값을 모두 0으로 바꾸기
# Date 열를 제거합니다.
df = df.drop('Date', axis = 1)
# 데이터 스케일링(MinMaxScaler 적용)
min_max_scaler = MinMaxScaler()
fitted = min_max_scaler.fit(df)
output = min_max_scaler.transform(df)
output = pd.DataFrame(output, columns=df.columns, index=list(df.index.values))
# 트레인셋/테스트셋 크기 설정
train_size = int(len(output)* 0.6) # 트레인셋은 전체의 60%
test_size = int(len(output)*0.3) + train_size # 테스트셋은 전체의 30%
#train/test 학습 및 라벨 설정
#종가를 예측하기 위해 종가를 label로 설정
train_x = np.array(output[:train_size])
train_y = np.array(output['Close'][:train_size])
test_x =np.array(output[train_size:test_size])
test_y = np.array(output['Close'][train_size:test_size])
validation_x = np.array(output[test_size:])
validation_y = np.array(output['Close'][test_size:])
# --- Keras를 이용한 딥러닝 수행 --- #
model = Sequential() # Keras 모델을 생성합니다.
# Keras 딥러닝 모델 학습을 위한 파라미터(옵션값)을 설정합니다.
# 현재 단계에서 각 파라미터에 대한 세부적인 내용까지 알 필요는 없으므로, 너무 걱정하지 마세요.
learning_rate = 0.01
training_cnt = 1000
batch_size = 100
input_size = 8
# 생성된 딥러닝 모델에 학습용 데이터(train_x)를 넣습니다.
# 마찬가지로 구체적인 코드를 처음부터 모두 이해하고 외울 필요는 없습니다.
model.add(Dense(input_size, activation='tanh', input_shape=(train_x.shape[1],)))
model.add(Dense(input_size * 3, activation='tanh'))
model.add(Dense(1, activation='tanh'))
# 데이터를 학습을 진행합니다.
model.compile(optimizer='sgd', loss='mse', metrics=['mae', 'mape','acc'])
model.summary()
history = model.fit(train_x, train_y, epochs=training_cnt,
batch_size=batch_size, verbose=1)
val_mse, val_mae, val_mape, val_acc = model.evaluate(test_x, test_y, verbose=0)딥러닝 모델 학습은 다음과 같이 진행됩니다.
- 전처리된 데이터를 준비
- Keras 모델을 생성
- 전처리된 데이터를 Keras 모델에 입력
- Keras 모델이 입력된 데이터를 학습
실습에 포함된 학습 파라미터는 다음과 같습니다.
- learning_rate(학습률): 학습 효율을 얼마나 좋게 할 것인지를 설정합니다. 효율이 크면 좋을 것 같지만, 이 경우 모델이 특정 데이터셋만 과하게 학습하기 때문에 모델이 보지 못한 새로운 데이터가 나타났을 때 제대로 예측하지 못합니다.
- training_cnt(반복횟수): 학습을 얼마나 오래 반복할 것인지를 설정합니다. 일반적으로 학습을 오래 반복할 수록 성능이 좋아지지만, 그만큼 학습 시간이 길어집니다.
- batch_size(회당 학습량): 한 번에 얼마나 많은 데이터를 학습할지를 설정합니다. 높을 수록 좋지만, 그만큼 더 많은 컴퓨터 성능을 요구하며 학습 속도가 느려집니다.

출력결과
일단 모르겠다..
찬찬히 분석해보자
Epoch 994/1000
63/63 [==============================] - 0s 16us/sample - loss: 0.0026 - mae: 0.0372 - mape: 128274.4609 - acc: 0.0159
Epoch 995/1000
63/63 [==============================] - 0s 18us/sample - loss: 0.0026 - mae: 0.0372 - mape: 128615.4922 - acc: 0.0159
Epoch 996/1000
63/63 [==============================] - 0s 16us/sample - loss: 0.0026 - mae: 0.0371 - mape: 128956.3047 - acc: 0.0159
Epoch 997/1000
63/63 [==============================] - 0s 16us/sample - loss: 0.0026 - mae: 0.0371 - mape: 129296.1562 - acc: 0.0159
Epoch 998/1000
63/63 [==============================] - 0s 16us/sample - loss: 0.0026 - mae: 0.0371 - mape: 129636.2344 - acc: 0.0159
Epoch 999/1000
63/63 [==============================] - 0s 16us/sample - loss: 0.0026 - mae: 0.0371 - mape: 129975.6406 - acc: 0.0159
Epoch 1000/1000
63/63 [==============================] - 0s 17us/sample - loss: 0.0026 - mae: 0.0371 - mape: 130315.2578 - acc: 0.0159

자 우선 54번 줄까지는 저번 강의에서 배운 데이터셋 나누기가 이루어진다.
이번 주차는 4강의 모두가 차례대로 하나씩 추가되는거라 이해가 쉽다 ;D

이제부터 새로운 내용 keras가 등장한다.

우선 Sequential은 tensorflow안의 keras. models 클래스에 존재하는 함수다

model자체를 바로 프린트해보면 Sequential 객체라는 설명 뿐 아직 아무것도 아닌듯 하다

60번 줄 다음으로 파라미터가 등장한다
저번 AndrewNg강의에서 배웠던 learning rate가 등장한다!!!
쉽게 예를 들면 분석대상성향을 만족하는 ax + b 같은 함수를 찾고자 한다면 a랑 b를 조금씩 변경하는 값들과 비슷하다. 나중에 배우도록 한다

69번줄. 학습용데이터를 넣어본다. 그 전강의에서 배운 train_x리스트를 여기다가 쓴다!
아까 sequential로 만들어본 model에 add함수를 써서 뭔가를 넣는다..

강의 들어보니까 다음에 실습과정에서 더 자세히 배운다니까는 일단 생략.

강조한 점은 저 history = model.fit에서 fit이 실제 학습을 진행한 다는 점이랑,

출력결과에서 loss, mae등은 오차를 표현하고 있다는 점만 일단 알아두자고 말씀하셨다
'파이썬 > NIPA 데이터분석 강의' 카테고리의 다른 글
| NIPA 데이터분석 첫번째 활용선택 : 03 Pandas 심화 -b pivot 피리부는사나이 (0) | 2020.09.30 |
|---|---|
| NIPA 데이터분석 첫번째 활용선택 : 03 Pandas 심화 -a apply group (0) | 2020.09.30 |
| NIPA 데이터분석 첫번째 활용선택 : 02 Pandas 기본 알아보기 (0) | 2020.09.29 |
| NIPA 데이터분석 첫번째 활용선택 : 01 NumPy와 연산 시작. (0) | 2020.09.29 |
| NIPA 데이터분석 첫번째 활용선택 : NumPy 사용해보기 (0) | 2020.09.29 |
| NIPA 온라인 데이터분석 체험 특강 : 04 그래프까지 (0) | 2020.09.26 |
| NIPA 온라인 데이터분석 체험 특강 : 02 주식데이터 기초 / pandas (0) | 2020.09.25 |
| NIPA 온라인 데이터분석 체험 특강 : 01 기초 점검 및 복습 (0) | 2020.09.24 |