
그다음 강의~
5분 남짓한개 5개? 정도 있어서
귀찮지만 않으면 다 들을 수 있다
화이팅하자!

1. 라이브러리 강의 그 두번째 시간 저번에 Numpy 다음으로 pandas라이브러리에 대해 배워보겠다
pandas란 구조화된 데이터를 효과적으로 처리하고 저장할 수 있는 파이썬 라이브러리다.
array 계산에 특화된 numpy를 기반으로 만들어져 다양한 기능을 제공한다.
특히 엑셀과 같은 스프레드 시트 등에 익숙하고 강력한 연산을 제공한다
2강에서는 시리즈 데이터와 데이터프레임에 대해 배워보겠다

2. 시리즈는 특수한 딕셔너리라고 보면 쉽다
numpy array가 보강된 형태다
pd.Series데이터를 만들면 오른쪽 처럼 나온다
인덱스는 0 1 2 3 으로 지정 값은 1 2 3 4 !!
결국 numpy array에 인덱스가 추가된다는 것 !!!!!

3. index = 로 하면 인덱스를 지정할 수 있다. 그리고 ['b']처럼 인덱스를 불러올 수 있다

4. 파이썬 딕셔너리 를 시리즈 형태로 만들어 줄 수 있다!

4-2. population.values로 하면 numpy array로 나온다는 점을 알 수 있다

5. 여러개의 series를 같이 합한걸 DataFrame이라 한다
pd.DataFrame({ 'population':population, 'gdp':gdp })

6. type(country['gdp'])를 프린트해보면
pandas.core.series.Series로 프린트된다

7. series도 연산자로 쓸 수 있다
gdp에서 인구수를 나눈 값을 gdp_per_capita에 저장. 그리고 그걸 column을 설정해서 추가하면 성공

8. 저장과 불러오기
저장을 하기위해서는 to_csv나 to_excel로 저장할 수 있다
csv는 comma seperate value 콤마로 분리된 값
읽어들이기 위해서는 read_csv 나 read_excel로 읽어들인다
이때 country 형태는 DataFrame
import numpy as np
import pandas as pd
# 두 개의 시리즈 데이터가 있습니다.
print("Population series data:")
population_dict = {
'korea': 5180,
'japan': 12718,
'china': 141500,
'usa': 32676
}
population = pd.Series(population_dict)
print(population, "\n")
print("GDP series data:")
gdp_dict = {
'korea': 169320000,
'japan': 516700000,
'china': 1409250000,
'usa': 2041280000,
}
gdp = pd.Series(gdp_dict)
print(gdp, "\n")
# 이곳에서 2개의 시리즈 값이 들어간 데이터프레임을 생성합니다.
print("Country DataFrame")
country = pd.DataFrame({
'population':population,
'gdp' : gdp
})
# 데이터 프레임에 gdp per capita 칼럼을 추가하고 출력합니다.
gdp_per_capita = country['gdp'] / country['population']
country['gdp per capita'] = gdp_per_capita
# 데이터 프레임을 만들었다면, index와 column도 각각 확인해보세요.
print(country.index)
print(country.columns)

재밌는 점
ㄱ. gdp per capita처럼 열의 이름을 설정할 때 띄어쓰기도 허용된다! _ 로 꼭 이어줄 필요가 없음.

9. 인덱싱과 슬라이싱
자료를 찾아가는 방식이 두가지가 있다
명시적인 인덱싱인 loc
china와 관련된 데이터를 뽑아주세요~하면 오른쪽 위 표처럼 출력된다 gdp population gdp per가 엔덱스로 바뀐다
이 뒤에 e+09같은 건 과학적 표기법이다
슬라이싱도 할 수 있다 : 을 이용

10. 다음으로 iloc이 있다
인덱스를 참고해서 잘라오는 파이썬 스타일 정수 인덱스로 찾아가는 법이다

+ ix라는 함수도 있었는데 (혼합임) 지금 지원이 중단돼서 안 쓴다

11. 새로운 데이터 추가/수정 방법에 대해 알아보겠다
columns에 이름을 선언.
dataframe.loc[0]명시적 인덱스에 순서대로 집어넣을 수 있다
[1]에 넣은 것처럼 딕셔너리로 넣을수도 있다
주의할 점은 [] 과 {}처럼 형태가 다르다는 점!!
[1, '이름'] = '영희'와 같이 그 해당 위치에 값을 변경할 수 있다.

12. DataFrame 새 컬럼 추가
np.nan으로 값을 일단 비워둠 (numpy의 not a number의 약자다) (숫자가 아닌 값 ) (빈 값)
len(dataFrame)의 경우
몇개의 데이터가 있는가? 0하고 1 두개니까 두개 출력

13. 다시 복습 하나만 있으면 series, 리스트로 들어가면 series가 연달아 있는 dataframe이다

14. 누락된 데이터 체크.
isnull 비어 있으면 TRUE
notnull은 비어있지 않으면 TRUE
nan이나 none같은 내용들을 체크한다

15. dropna()를 통해 nan이 있는 값들을 아예 삭제할 수 있다. 비어있는 row를 삭제한다
fillna()의 경우 nan이 있는 값들을 특정 string이나 다른 값으로 채워준다 그리고 그걸 '전화번호'라는 시리즈 데이터로 만들어준다. 이걸 다시 dataframe에 전화번호로 대체한다

16. 인덱스가 다른 배열에 대해서는 인덱스에 맞춰서 더해준다!
0 과 3은 서로 상대방이 없으므로 NaN이 된다
이 때 add라는 함수를 사용하면 비어 있는 값들을 한꺼번에 처리해준다.

17. 연산자 가능하다!!
list("AB")의 경우 A B 따로 떨어뜨려 columns에 적용하게 된다
마찬가지로 A의 경우 2 2 여서 3 3 인 B에 비해 작아 NaN이 나타나게 되는데
이걸 add(B, fill_value = 0)을 통해 자동적으로 0값을 적용하게 해준다.
이때도 A, B도 맞는 열과 행 값에 따라 더해준다!!!

18. 집계함수
numpy array 에서 사용했던 sum, mean 등을 활용할 수 있다.
여기서 sum() mean()은 각 열에 맞게 더해준다

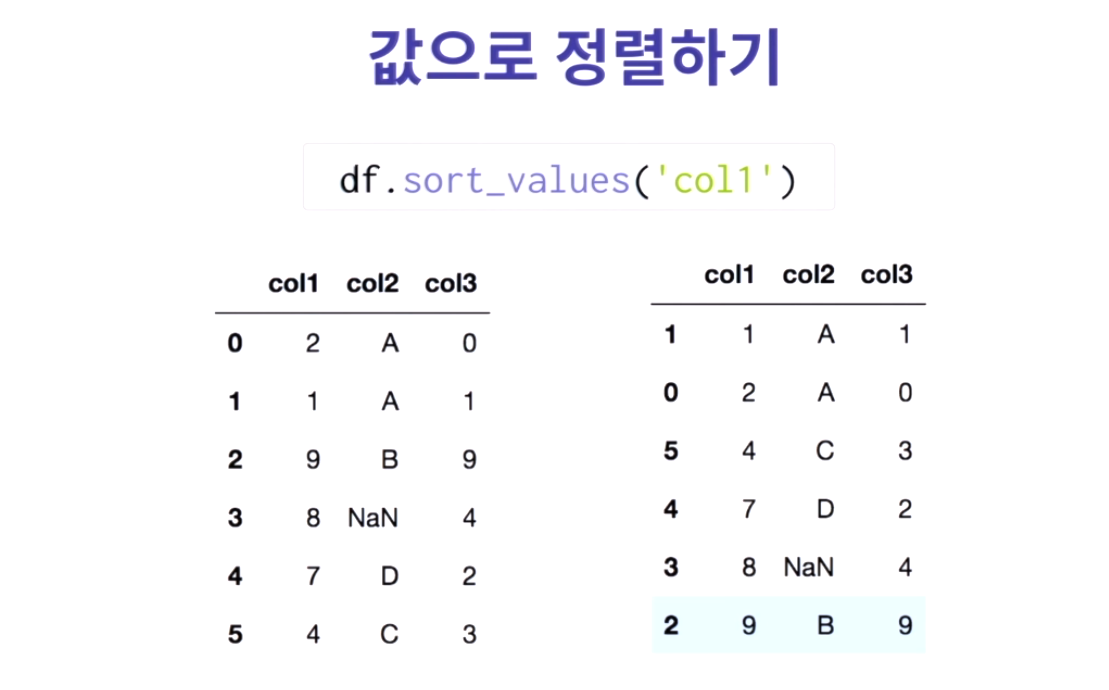
19. sort_values('col1')칼럼 값에 맞게 정렬이 된다

20. 내림차순으로 정렬하게 위해선 ascending = False인자 값을 주면 된다

21. 두개의 칼럼을 줄 때는 col2를 먼저 정렬하고 같은 값에 대해서는 col1에 대해 정렬해주세요라는 명령이다.
Nan은 가장 마지막 순서다
import numpy as np
import pandas as pd
print("DataFrame: ")
df = pd.DataFrame({
'col1' : [2, 1, 9, 8, 7, 4],
'col2' : ['A', 'A', 'B', np.nan, 'D', 'C'],
'col3': [0, 1, 9, 4, 2, 3],
})
print(df, "\n")
# 정렬 코드 입력해보기
# Q1. col1을 기준으로 오름차순으로 정렬하기.
sorted_df1 = df.sort_values('col1', ascending= True)
# Q2. col2를 기준으로 내림차순으로 정렬하기.
sorted_df2 = df.sort_values('col2', ascending = False)
# Q3. col2를 기준으로 오름차순으로, col1를 기준으로 내림차순으로 정렬하기.
sorted_df3 = df.sort_values(['col2','col1'], ascending = [True, False])22. 만약 col2는 오름차순 col1은 내림차순으로 정렬하기 원한다면 저렇게 리스트로 각각 묶는 방식이 있다.
sort_values('col2','col1')로 쓰면 안된다
23. 실습 : 잭 콩나물
from elice_utils import EliceUtils
import pandas as pd
elice_utils = EliceUtils()
def main():
# ./data/tree_data.csv 파일을 읽어서 작업해보세요!
tree = pd.read_csv('./data/tree_data.csv')
# print(tree)
# print(type(tree)) <class 'pandas.core.frame.DataFrame'>
tree.sort_values('height', ascending= False)
print(tree.loc[0])
if __name__ == "__main__":
main()
크 한번에 성공!

강의에서는 누락된 데이터 여부를 확인한다
이것도 실전에서는 중요할듯

그리고 저장하는 to_csv와
head를 통해 상위 5개만 가져오는 것 같은 함수도 추가적으로 사용해봤다
'파이썬 > NIPA 데이터분석 강의' 카테고리의 다른 글
| NIPA 데이터분석 첫번째 활용선택 : 04 Matplotlib 2 - with pandas (0) | 2020.09.30 |
|---|---|
| NIPA 데이터분석 첫번째 활용선택 : 04 Matplotlib 1 - line plot 옵션과 scatter bar hist (0) | 2020.09.30 |
| NIPA 데이터분석 첫번째 활용선택 : 03 Pandas 심화 -b pivot 피리부는사나이 (0) | 2020.09.30 |
| NIPA 데이터분석 첫번째 활용선택 : 03 Pandas 심화 -a apply group (0) | 2020.09.30 |
| NIPA 데이터분석 첫번째 활용선택 : 01 NumPy와 연산 시작. (0) | 2020.09.29 |
| NIPA 데이터분석 첫번째 활용선택 : NumPy 사용해보기 (0) | 2020.09.29 |
| NIPA 온라인 데이터분석 체험 특강 : 04 그래프까지 (0) | 2020.09.26 |
| NIPA 온라인 데이터분석 체험 특강 : 03 입력피처, 데이터셋나누기, kendas맛보기까지 (0) | 2020.09.26 |