
activation function이라고 부른다.
어떤 값 이상일 때 activate하기 때문에
NN for XOR
이렇게 순차적으로 읽게 했었다.
lets go deep & wide
그림으로 그리면 이렇게 나오죠 (오른쪽 박스 세개)
input ------- > output layer
안은 hidden layer이라고 한다. 입력 아웃풋에서는 보이지 않으므로
9단으로 해볼까?
2->5 이렇게 시작하는데 꼭 5개여야 하는거 아닌거 알지?
텐서보드로 하면 잘 나온다.
엥 0.5가 나온다.
이 문제가 바로 tensorboard cost & accruacy
왜 이 문제가 발생할까?
backpropagation 2~3단 정도에서는 오케이지만 우리가 9~10단이면 못 해결한다.
저번에 배웠던 backpropagation chain rule 생각나냐?
미분 값을 구하고 싶을 때 g의 미분값 g에서의 로컬 값을 곱해서 구했었다.
y가 다른 쪽에서 왔다고 해보자
y의 범위는 0~1사이겠지.
sigmoid함수 기억하면 0보다 작은 값으면 0에 가깝고..
그러므로 이 미분값은 0.01 * g ???
어쩄든 그래서 항상 1보다 작은 값이고 0.01 * 0.01 * 0.03 = 0.000? 굉장히 작은 값이 된다.
별로 영향을 미치지 않게 된다.
vanishing gradient
최종단에 걸쳐있는 경사 기울기는 진하지만 앞부분은 경사 기울기의 영향이 매우 작아진다.
이 문제 때문에 2차 winter에 들어가게 된다.
hinton은 sigmoid 를 잘못 썼다고 진단
sigmoid를 썼었다. 하지만 이 0~1로 나오는 거 말고 다른 방식 없을까?
reLU값이 나왔다.
0보다 작으면 아예 꺼버림
rectified linear unit
시그모이드 대신 렐루를 그대로 대입하면 된다.
max(0, x) 이 값이 된다??
relu를 적용
마지막단은 0~1 사이 출력이어야 하기 때문에 sigmoid그대로 사용
결과 아주 잘 나온다.
cost 급격히 줄어드는 모습
relu 말고도 계속 응용
leaky relu 0.1x
elu 0이 아니라 어떤 값
maxout
등등 응용
sigmoid 응용
tanh 0중심 -1~1
조사해봤는데 정확도
sigmoid굉장히 나쁘다. costfunction 안 내려간다.
relu vlrelu 좋다
==========================================
다음문제 weight 초기법
저번에 배운 vanishing gradient 문제
해결법에는 첫번쨰 relu 사용이 있었고
두번째는 weight 초기화
hinton은 초기값을 멍청하다고 했ㄷ.
아까 cost function 값을 보면
relu 두번 돌렸는데 랜덤 값에 따라서 cost 가 줄어드는 속도가 다르다.
set all inital weights to 0
한다면 gradient가 사라진다. ???
따라서 절대로 다 0이어서는 안된다.
그러면 학습이 안된다.
hinton은 결국 어떻게 학습시키느냐의 문제였는데 그것이 바로
restricted boatman machine RBM
요즘 안 사용하지만 그래도 알아두면 좋다.
이걸 사용한 것이 바로 deep relief ?
어떤 입력이 있어.
그러면 weight 곱해서 그다음 값을 나온다.
계속 값을 만들고 그 값에 따라서 weight 조정
반대로 거꾸로 하는 방법 backward
거꾸로 쏘아준다.
뭘 비교하냐면
앞으로 간 값과 뒤로 간 값을 비교한다. 똑같이 되도록 weight 조절
이걸 restricted boatman machine
인코드 디코드 라고도 한다.
이것을 가지고 weight 초기화
어떻게??
나머지는 신경쓰지 말고 두개만 일단 신경 쓴다. 그리고 나서 weight 학습 -> 다음 꺼로 넘어간다.
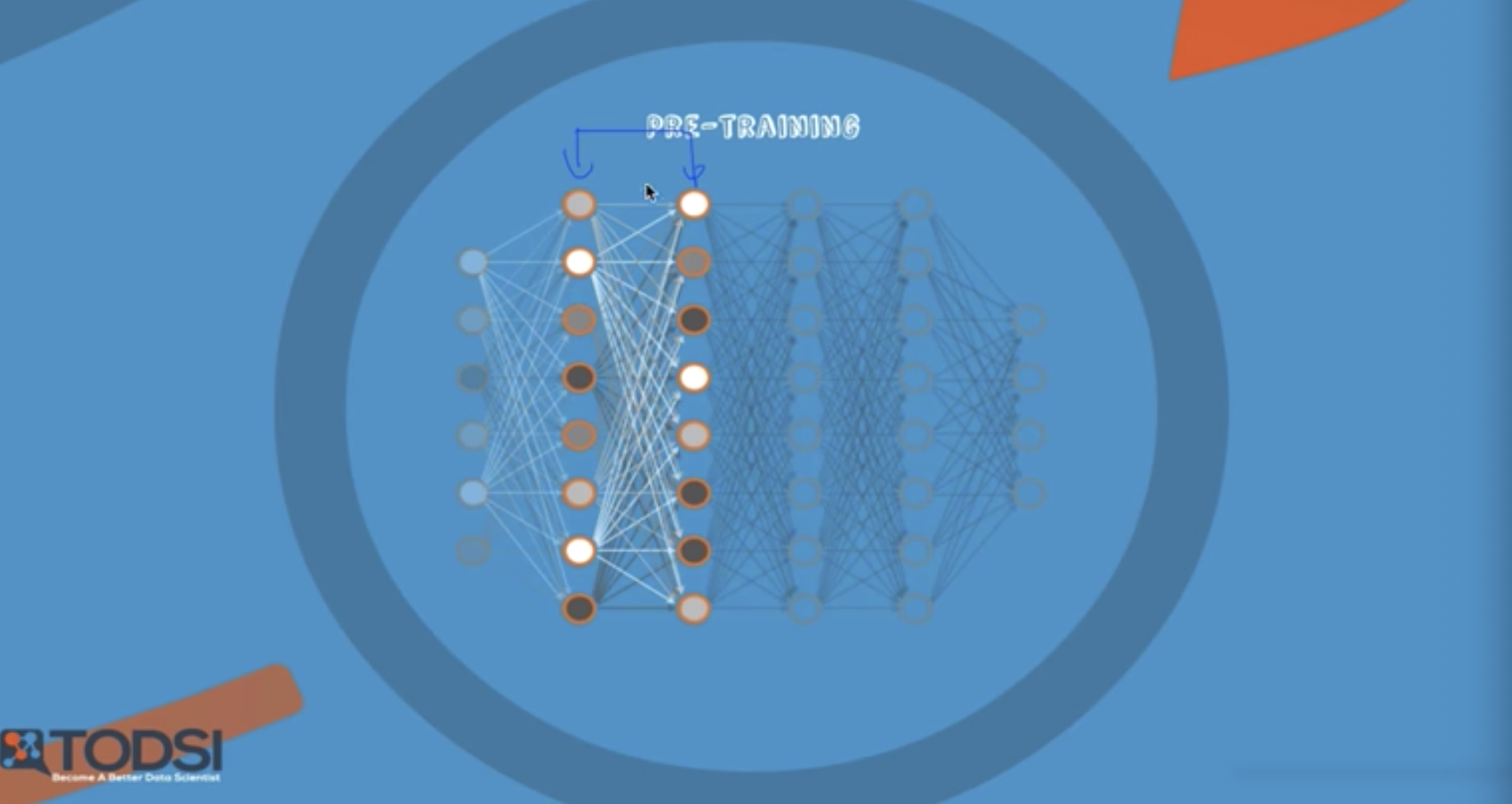
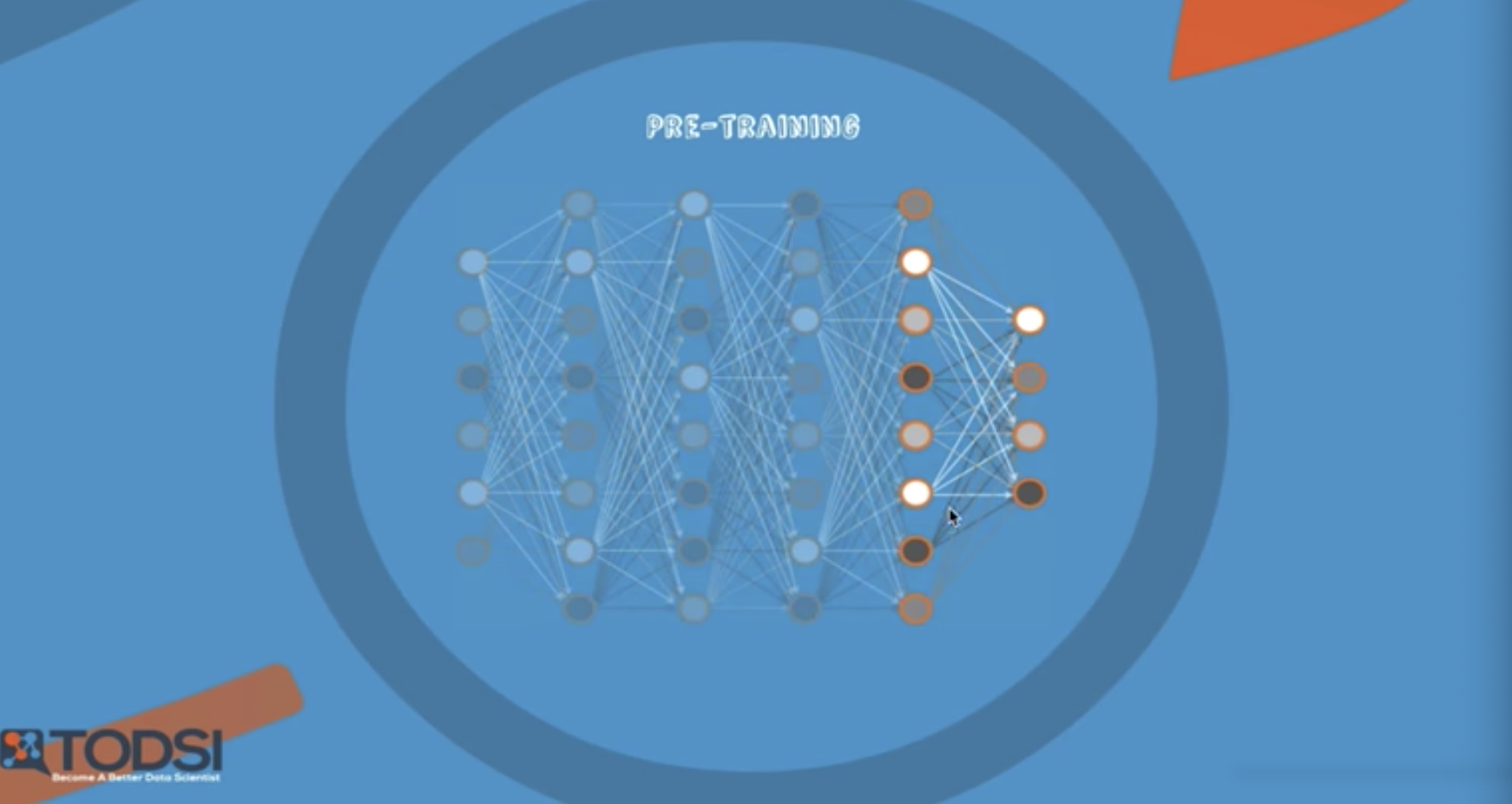
다음으로 pretraining
계속 마지막으로 진행
weight 값이 초기화 값인 것
실제로 x 학습하듯이 시켰어
fine-tuning 이라고 부르기도, 이미 rate가 훌륭해서
초기화 값을 잘 주면 됩니다.
좋은 소식은 rbm을 안 써도 된다.
굉장히 쉬운 알고리즘이 나옴
입력 노드에 맞게 비례해서 준다.
xavier/he initialization
입력 과 출력 개수?에 따라서 주면된다고
rbm이랑 비슷하게 잘한다는 것을 발견
he 홍콩 교수
이분은 초기값을 /2 를 또하더라.. 근데 또 잘됨
ㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋ
실습 보면 깜짝 놀랄만도
연구자들이 여러 방식으로 초기화 값을 실행해봤더니
차이가 있지만 잘 되더라
이 분야는 아직 연구가 많다.
결론적으로 여러 알고리즘을 실행해보고
잘 되는 것을 쓰면 되겠다.
=====================================
dropout과 model 앙상블
overfitting 기억 나나??
실제 테스트 케이스는 0.99지만
한번도 보지 못한 테스트 데이터에대해서는 낮다.. 안 좋다
응용력이 없다.
그래프로 나타나면 test accuravy 0.85 ;;;
레이어가 많을수록 에러가 떨어져야 한다. (파란색)
근데 trainingn 넣자 레이어 많아질 수록 에러가 다시 높아짐
solution for overfitting
=> regularizaiton
regularization
not too big number in the weight
dropout : a simple way to prevent neural network from overfitting
보통 이런데
확 끊어버리는 거
왜 되는가???
랜덤하게 쉬게해서 구현한 것
이걸 구현해보면 dropout이라는 레이어를 -> 다음 레이어로 보내는 것
dropout_rate 0.5면 반은 떨어짐
학습하는 동안에서 줄여야한다. 실전에는 dropout rate 은 1 이어야 한다.
학습할 때!!
평가하거나 적용할 때는 1 이어야
ensemble
앙상블 ??
이건 독립적으로 집단을 만들고 각각 9단을 만들어서 학습
결과가 조금씩 다르겠지 그리고 합쳐
전문가 한분 한분 따로따로 독립되게 물어봄
실제 해보면 성능이 2~4~5%까지 향상된다.
=============================================
이제 원하는 대로 모델을 쌓는다 레고 같다.
feedforward neural network 그냥 순서대로 쌓는다.
fastforward
이거는 모델을 쌓고 두단씩 뛰어넘는 것
He가 만든 3% 이하로 만든 이미지넷 회신율?을 만든 네트워크 구조
기발하고 새롭다.
split & merge
두개로 나뉘고 만나고 갈라지고..
처음부터 나눠서 입력 모이고 쌓이는 방식
composational model ???
recurrent network
옆으로 나가는 거
RNN이다.
우리들 만의 nn을 만들 수 있다.
================================
첫번쨰 softmax classifier for MNIST
90%
hypot~ optimizer 까지가 세줄 모델 나머지는 돌리는 거
다음은 nn for mnist
이건 w, b 가 중요하지 우리가 정하면 된다.
중간 순자들은 입력 나름 우리가 정하면 된다.
마지막은 10개 로 정해져있다.
relu 사용했다. 94% 정확도
초기화를 잘해야한다. xavier initialization tensorflow
sungkim 이 한줄로 그대로 코드 가져옴
바뀐거 거의 없고 대신 값 초기화 할 때 initlalizer()라는 거 있음
처음부터 cost가 매우 낮다.
5단까지 늘렸다. 깊고 넓게 돌림
9742로 더 떨어졌다. 왜?
overfitting
기억을 다 해버린다. 새로운 테스팅 케이스가 나오면 accuracy가 떨어지는 케이스
그래서 드랍아웃이 등장
dropout 사용했다. 그렇게 되면 0.9804??? 와우!
학습을 할 때는 0.5~0.7 드랍아웃
하지만 테스팅 평가는 반드시 1
이 keep_prop은 placeholder로 정한다.
학습에서는 0.7인데
마지막에 keep_prob = 1로 정한다.
이정도면 크게 늘린거다.
optimizer 굉장히 많다.
이 사이트에 가면 어떤 것이 잘 되는지 알 수있다.
adam이 상당히 좋은 결과를 만들어낸다.
adam optimizer 그대로 쓰면 된다.
'머신러닝,딥러닝 > tensorflow' 카테고리의 다른 글
| lec12 NN의 꽃 RNN 이야기 (0) | 2021.02.10 |
|---|---|
| lec11 CNN basics tensorflow (0) | 2021.01.25 |
| lec11 ConvNet 의 conv 레이어 만들기 (0) | 2021.01.25 |
| lec09 XOR 문제 딥러닝으로 풀기 (0) | 2021.01.24 |
| lec08 tensor manipulation(reshape, stack, zip, one_hot ..) (0) | 2021.01.22 |
| lec08 deep neural network for everyone (0) | 2021.01.22 |
| lec07 learning rate, data preprocessing overfitting (0) | 2021.01.21 |
| lec06 multinominal 개념 소개 (0) | 2021.01.21 |