[Python] 네이버 블로그 Selenium 웹 크롤링
Selenium을 이용한 웹 크롤링네이버 블로그에 "대구 여행" 키워드를 검색하면 뜨는 Top100개...
blog.naver.com
네이버 블로그 탑 100 웹 크롤링 하고 싶었는데
음 top 10만 끌어모으는게 단점
page에서 다음으로 넘어가는게 잘 안됨
import platform
import time
import datetime
import matplotlib.pyplot as plt
import requests
from bs4 import BeautifulSoup
from selenium import webdriver
import csv
path = "c:/Windows/Fonts/arial.ttf"
from matplotlib import font_manager, rc
if platform.system() == 'Darwin':
rc('font',family = 'AppleGothic')
elif platform.system() == 'Windows':
font_name = font_manager.FontProperties(fname=path).get_name()
rc('font', family=font_name)
else:
print('Unknown system... sorry~~~')
plt.rcParams['axes.unicode_minus'] = False
#Chrome driver path
driver = webdriver.Chrome('c:/Users/user/Downloads/chromedriver.exe')
def blog_crawling(page):
url = "https://search.naver.com/search.naver?where=post&sm=tab_jum&query=%EB%8C%80%EA%B5%AC%EC%97%AC%ED%96%89"
driver.get(url)
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
blog_post_list = []
print('blog crawling start!')
for links in soup.select('li.sh_blog_top > dl'):
title = links.select('dt > a')
title = title[0].get('title')
date = links.select('dd')
date = date[0].text
## 3hours earlier..
now = datetime.datetime.now()
if '시간 전 ' in date:
date = now.strfttime('%Y.%m.%d')
elif '일 전 ' in date:
temp = int(date[0:1])
temp = datetime.timedelta(days = temp)
date = datetime.datetime.now() - temp
date = date.strftime('%Y.%m.%d')
elif '어제 ' in date:
temp = datetime.timedelta(days= 1)
date = datetime.datetime.now() - temp
date = date.strftime('%Y.%m.%d')
href = links.select('dt > a ')
href = href[0].get('href')
blog_post = {'title' : title, 'date' : date, 'href' : href}
blog_post_list.append(blog_post)
print(blog_post)
n = len(blog_post_list)
print('blog_post_list = ', blog_post_list)
return blog_post_list
def save_data(blog_post):
keys = blog_post[0].keys()
with open('blog_crawling17.csv', 'w') as file:
writer = csv.DictWriter(file, keys)
writer.writeheader()
writer.writerows(blog_post)
print('success save data')
blog_post_list = []
for i in range(1, 100, 10):
blog_post_list.extend(blog_crawling(page=i))
print("page = ", i)
time.sleep(2)
#blog_post_list.extend(blog_crawling(page=2))
save_data(blog_post_list)
이런식으로 탭이 하나 생기고
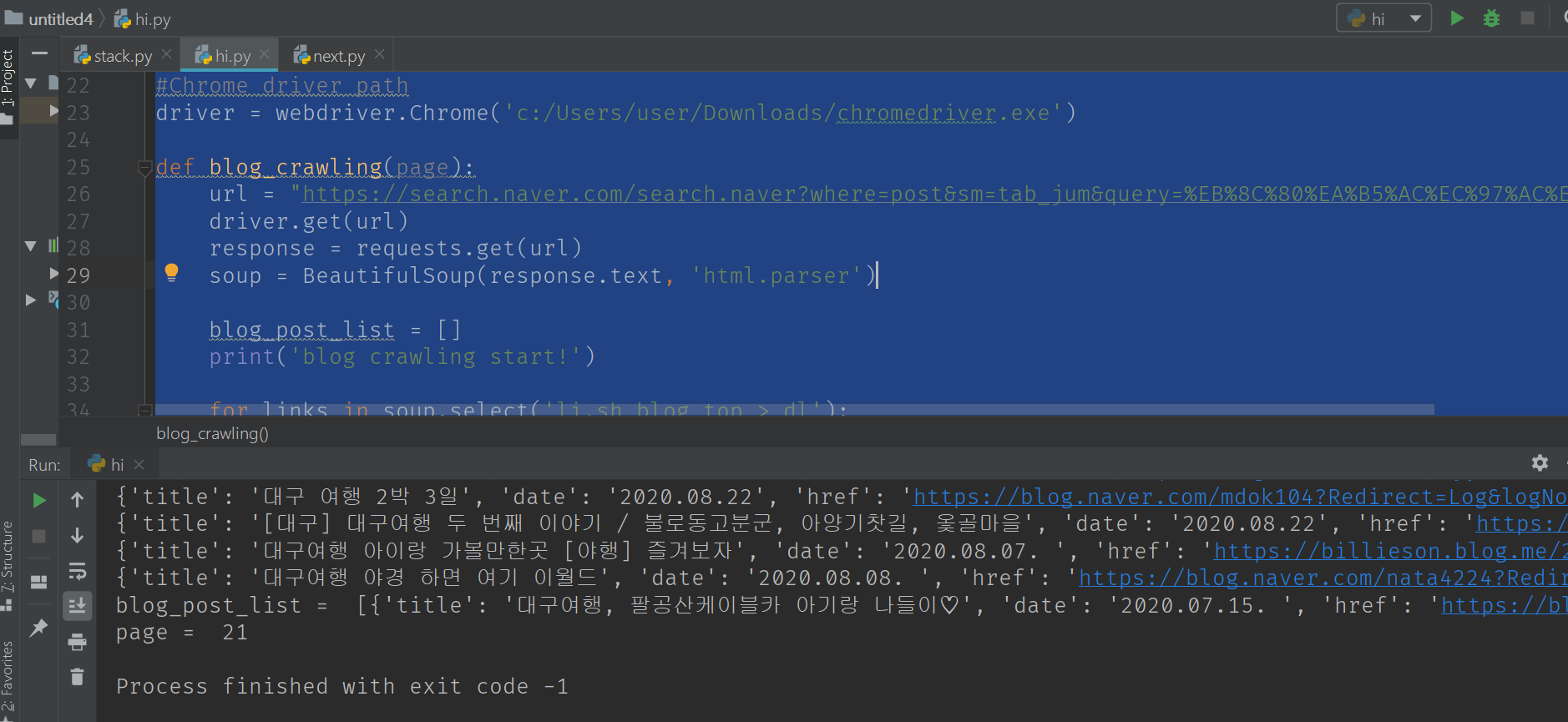
밑에 이렇게 프린트가 됨
success!하면

자료를 저장한 엑셀파일도 저장됨 !!
가운데에 driver을 위해선
https://beomi.github.io/2016/12/27/Django-TDD-Study-01-Setting-DevEnviron/
[DjangoTDDStudy] #01: 개발환경 세팅하기(Selenium / ChromeDriver) - Beomi's Tech blog
Web을 직접 테스트한다고? 웹 서비스를 개발하는 과정에서 꼭 필요한 것이 있다. 바로 실제로 기능이 동작하는지 테스트 하는 것. 이 테스트를 개발자가 직접 할 수도 있고, 혹은 전문적으로 테스
beomi.github.io
사이트를 참고해 driver을 다운받아 올바른 PATH에 저장해야 한다.

나같은 경우 다운로드 폴더에 압축파일을 풀어서 exe파일을 두었다면
내가 참고한 블로그의 경우 pycharm project ~~ 어딘가에 설치했으니 다 각자 위치 잘 확인하기
참고로 이 selenium은 firefox를 기본으로 하기 때문에 driver을 chrome으로 설치해야 연동 가능하다고 한다.
올바른 driver은
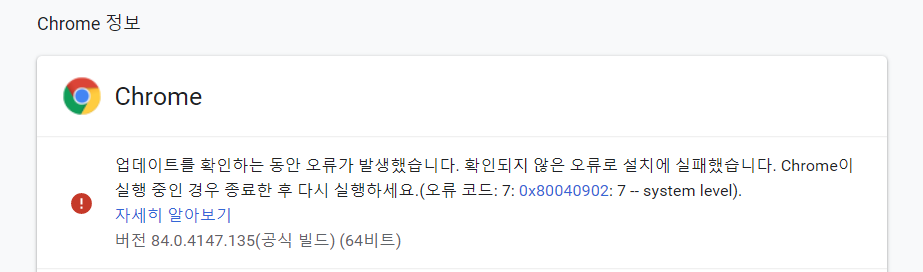
크롬 정보에서 확인해서 설치하기 (크롬 맞춤설정 -> 도움말 -> 크롬 정보)
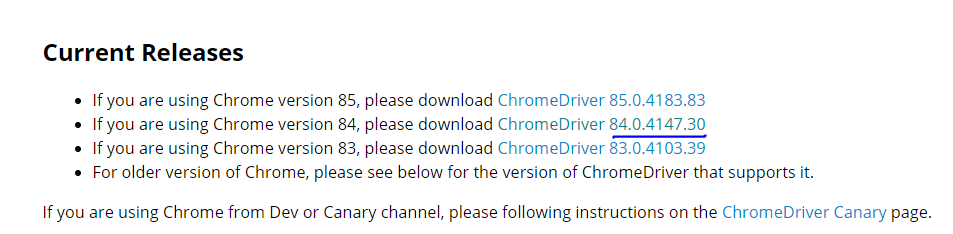
나는 버전 84니깐 두번째 84를 설치하면 된다.
근데 위는 page를 옮기는 거에 실패한 코드
page = 1, 11, 21 이렇게 옮겨져야 하는데
page = 1에서만 머물고 다음 url을 불러오는데 계속 실패함
https://nittaku.tistory.com/373
19. requests.get('')으로 url속 html 받아온 뒤 -> bs4를 이용한 < 해당페이지 scrapping >
프로젝트 : web_scraping_study_no1 파일명 : watch_court.py requests 패키지 설치 및 requests.get('') 이용하여 홈페이지에서 주소 가져오기 어떤 사이트의 게시판에 들어갔을 때, request url이 안뜰 수 있다..
nittaku.tistory.com
위에 코드를 참고해서 url을 조금 바꿔주니 성공!!!
import platform
import time
import datetime
import matplotlib.pyplot as plt
import requests
from bs4 import BeautifulSoup
from selenium import webdriver
import csv
path = "c:/Windows/Fonts/arial.ttf"
from matplotlib import font_manager, rc
if platform.system() == 'Darwin':
rc('font',family = 'AppleGothic')
elif platform.system() == 'Windows':
font_name = font_manager.FontProperties(fname=path).get_name()
rc('font', family=font_name)
else:
print('Unknown system... sorry~~~')
plt.rcParams['axes.unicode_minus'] = False
#Chrome driver path
driver = webdriver.Chrome('c:/Users/user/Downloads/chromedriver.exe')
def blog_crawling(page):
url = "https://search.naver.com/search.naver?date_from=&date_option=0&date_to=&dup_remove=1&nso=&post_blogurl=&post_blogurl_without=&query=%EB%8C%80%EA%B5%AC%EC%97%AC%ED%96%89&sm=tab_pge&srchby=all&st=sim&where=post&start={}".format(page)
driver.get(url)
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
blog_post_list = []
print('blog crawling start!')
for links in soup.select('li.sh_blog_top > dl'):
title = links.select('dt > a')
title = title[0].get('title')
date = links.select('dd')
date = date[0].text
## 3hours earlier..
now = datetime.datetime.now()
if '시간 전 ' in date:
date = now.strftime('%Y.%m.%d')
elif '일 전 ' in date:
temp = int(date[0:1])
temp = datetime.timedelta(days = temp)
date = datetime.datetime.now() - temp
date = date.strftime('%Y.%m.%d')
elif '어제 ' in date:
temp = datetime.timedelta(days= 1)
date = datetime.datetime.now() - temp
date = date.strftime('%Y.%m.%d')
href = links.select('dt > a ')
href = href[0].get('href')
blog_post = {'title' : title, 'date' : date, 'href' : href}
blog_post_list.append(blog_post)
print(blog_post)
n = len(blog_post_list)
print('blog_post_list = ', blog_post_list)
return blog_post_list
def save_data(blog_post):
keys = blog_post[0].keys()
with open('blog_crawling17.csv', 'w') as file:
writer = csv.DictWriter(file, keys)
writer.writeheader()
writer.writerows(blog_post)
print('success save data')
blog_post_list = []
for i in range(1, 100, 10):
blog_post_list.extend(blog_crawling(page=i))
print("page = ", i)
time.sleep(2)
#blog_post_list.extend(blog_crawling(page=2))
save_data(blog_post_list)
차이점은
처음 url은
를 참고했다면
다음 코드의 url은
을 참고함
차이는 뒤에 'start=1'부분
다음 페이지로 넘어가면 start = 11, 21 이렇게 넘어간다.
따라서 이부분을 page라는 변수처리만 해주면 탑100까지 다 호환가능

이렇게 .format 형식을 써서 {}부분을 바꿀 수 있게 되었다!!!
이렇게 100개 성공!
:D
'파이썬' 카테고리의 다른 글
| 파이썬 urlopen()함수 예제 - Request 클래스로 요청 헤더 지정 (0) | 2020.09.10 |
|---|---|
| [장고&파이썬웹] urllib.request 모듈 예제 재작성 (0) | 2020.09.06 |
| 홍련화 가사 html for li in lis with xpath (0) | 2020.08.29 |
| 파이썬 네이버 블로그 크롤링 더 깔끔한 코드! (0) | 2020.08.26 |
| 파이썬 웹크롤링 연습 : 알고리즘 기초 사이트 : get text (0) | 2020.08.24 |
| 파이썬 웹 크롤링 3. find_all, import re, get text (0) | 2020.08.24 |
| 파이썬 웹 크롤링(Web Crawling) 2. html긁어모으기/태그검색 (3) | 2020.08.24 |
| 파이썬 웹 크롤링(Web Crawling) 1. 파이썬 pip설치 및 옵션 (0) | 2020.08.24 |