Introduction Deepwalk 등장 배경

그래프는 실생활에서 다양하게 사용되고 있습니다. 그 예로는 팔로우와 팔로워 관계를 나타내는 소셜 네트워크, 분자구조 그래프 등이 존재합니다. 연구자는 이런 그래프 데이터에서 network classification, content recommendation, anomaly detection, 등 같은 머신러닝 태스크를 적용해보고 싶어질 수 있습니다. 하지만 그래프 데이터를 그대로 기존 머신러닝과 딥러닝 분류 모델에 적용하기에는 한계가 존재하기 때문에 그래프를 더 낮은 차원으로 임베딩해주는 그래프 임베딩 방식이 발전해왔습니다.

DeepWalk는 대표적인 graph embedding method입니다, Randomwalk라는 방법으로 그래프를 일련의 시퀀스 집합으로 재해석하고 언어모델의 논리에 적용해서 그래프의 구조를 벡터 집합으로 표현하는데 성공했습니다.
DeepWalk의 contribution은 다음과 같습니다.
DeepWalk는 짧은 randomwalks를 이용해 그래프의 구조를 잡아냈습니다.
기존 베이스라인 모델들과 비교해 레이블이 적은 데이터에 대해서도 뛰어난 성능을 보였습니다.
또한 deepwalk는 병렬 처리가 가능해 실제 현실에 존재하는 거대한 그래프 데이터도 분석 가능합니다.
Problem Definition 문제 정의

DeepWalk가 풀고자하는 문제는 그래프를 노드 개수보다 더 적은 차원으로 표현하는 것입니다.
만약 세 개의 노드가 위 그림처럼 연결되어 있을 때 첫번째 행은 2 3 번째 칸에 1값이 들어가게 되고, 두번쨰 행은 2번 노드와 1번노드만 연결되어 있으므로 첫번째 값만 값이 채워지게 됩니다. 세번째 행 역시 2번 노드와 같은 모습을 보입니다.
이렇게 세 개의 노드만으로 벌써 3*3 즉 9 크기의 매트릭스가 나왔는데 만약 10만개 100만개 점이 들어있는 그래프를 해석해야 하면 인접행렬은 그의 제곱만큼 크기를 갖게 됩니다.

따라서 Deepwalk는 Input으로 해당 Graph = (V, E, X, Y) 와 하이퍼파라미터(window size w, embedding size d…)가 주어졌을 때 output으로는 각 노드를 d 차원의 vector로 표현한 결과를 돌려주는 것을 목표로 합니다. 이 d차원의 벡터는 노드가 단순히 어떤 노드와 연결되어 있다는 정보에 그치지 않고 노드 간의 상관관계와 같은 그래프 정보도 함축하게 됩니다.
그 결과로 얻은 벡터는 앞에서 언급했던 여러 머신러닝, 딥러닝 모델에 사용할 수 있습니다.

여기서 고려할 점은 원래 그래프에서 점들간의 관계와 representation 값에서 나타나는 점들 간의 관계가 최대한 유사하게 유지되어야 한다는 점입니다. 즉 원래 가까웠던 점들은 representation space에서도 벡터 값이 유사해야 합니다.
Basic Concepts (background)
Random walk

Random walk는 한 노드에서 출발해 엣지로 연결된 임의의 이웃으로 계속 이동해서 만들어진 노드 시퀀스를 의미합니다.
논문에서는 이를 W로 표현했습니다. Wvi는 i번째 Vertex에서 하이퍼 파라미터로 주어지는 walk length만큼의 길이로 만들어진 노드 시퀀스를 의미합니다.
그림에서 예를 들자면 만약 1번째 vertex에서 5 길이만큼의 random walk를 만든다면 1과 이어진 2, 3, 4 중 하나에 도달할 것입니다. 만약 2로 갔다면 그 다음 노드는 또 2의 이웃으로 가서 쭉 만들어집니다.
Skip-gram

Random walk를 통해 만들어진 노드 시퀀스는 이 skip gram 방법론에서 사용됩니다.
언어모델 방법론인 Word2vec에서는 단어를 임베딩하는 방법으로 두 가지가 존재합니다. 하나는 주변단어로 중심단어를 학습하는 CBOW 방식이며 반대로 중심단어로 주변단어를 학습하면 Skip gram 방식이 됩니다. Deepwalk는 이 중 skip gram 방법론을 사용했습니다.
Skip gram은 실제 문장들에서 비슷한 위치에 있는 단어들은 embedding space에서도 비슷한 위치에 있을 것으로 가정해, 중심단어가 주어졌을 때 주변단어가 나타날 확률을 최대화합니다. 이를 그래프에 적용해보면 특정 노드가 주어졌을 때 주변 이웃으로 어떤 노드가 나타날지 그 확률을 최대화하게 된다고 볼 수 있습니다

정리하면 언어모델에서는 단어와 단어의 시퀀스인 문장이 있다면
DeepWalk에서는 단어와 대응하는 vertex와 vertex의 시퀀스인 random walk가 존재합니다.
단어를 임베딩하기 위해 문장에서 주변 단어와의 관계를 탐색하듯이
그래프에서는 vertex 즉 노드의 정보를 임베딩하기 위해 노드의 시퀀스인 random walk를 skip gram에 적용하게 됩니다.
Hierarchical Softmax

Deepwalk 알고리즘에서는 그래프를 균형 잡힌 binary tree로 만드는 과정이 존재합니다. 이는 skip gram에서 단어에 대한 각 확률을 계산할 때 계산 비용을 줄이기 위해 hierarchical softmax를 사용하기 때문입니다.
Hierarchical softmax는 이진 분류를 통해 단어 확률을 계산하는 방식입니다.
위의 그림에서 단어 I’m을 예측하기 위해서 출발점부터 왼쪽 또는 오른쪽으로 갈 확률을 고려하게 됩니다.
본래 10만개의 노드 꼭짓점이 존재하면 내적을 그만큼 진행해야 했지만 hierarchical softmax는 log를 취하므로 계산량이 크게 줄어듭니다.
여기서 huffman coding을 통해 자주 만나게 되는 vertex를 고려하게 되면 도달하는 시간을 더 줄일 수 있다고 합니다.
Experiments Explained
Deepwalk 실험은 세 가지 데이터셋으로 진행하였고 파라미터 변화에 따른 차이도 실험했습니다.

실험을 진행한 데이터셋은 - BlogCatalog- Flickr- YouTube 가 있고
표에서 볼 수 있듯이 blogCatalog, flickr, youtube 순서로 그래프 크기가 커지는 것을 알 수 있습니다.

먼저 가장 작은 그래프 데이터인 BlogCatalog 그래프에서는 레이블된 노드가 10~90%일 때 성능을 살펴봤습니다.
결론적으로 DeepWalk는 label을 가진 노드가 적을 때 좋은 성능을 보였습니다.
10%~20% 노드만이 레이블이 있을 때 다른 모델에 비해 성능이 좋았고
70~90% 노드가 레이블을 가지게 되면 SpectralClustering이 더 성능이 좋았던 것을 알 수 있습니다.

중간 사이즈 그래프인 Flickr 데이터셋 실험입니다.
여기서는 labeled node가 1~10% 이내일 때 성능을 측정했습니다.
이때는 DeepWalk 성능이 모든 케이스에서 대체로 좋은 것을 알 수 있습니다.

YouTube 네트워크 데이터셋는 앞의 두 데이터셋에 비해 매우 큰 그래프입니다.
이 그래프는 너무 커서 SpectralClustering과 Modularity 모델은 이 데이터셋으로 학습을 진행할 수 없었습니다.
유튜브 데이터셋 실험결과로 Deepwalk는 퍼센티지에 상관없이 좋은 성능을 보였고 이는 굉장히 큰 데이터에 대해서도 적응을 잘하는 것을 알 수 있습니다.

다음으로 파라미터 실험을 위해 논문은 window size를 10, walk length를 40으로 고정한 채, 여러 파라미터에 변화를 주며 실험을 진행했습니다.
위의 line graph는 dimension의 크기를 x axis로 두고 y axis로 f1 score가 나와있는 그래프입니다.
먼저 색깔에 따라 training data 크기가 다른데, training data 수가 많을수록 f1 score가 높았습니다.
그리고 dimension을 살펴보면 training data 크기에 따라 달랐지만 대체로 64~128 사이즈일 때 성능이 좋았습니다.

이번에는 gamma 값이 1, 3, 10, 30, 50, 90일 때 성능 비교를 한 그림입니다.
gamma 1, 3, 10으로 올라갈 때는 개선 폭이 커졌지만 30, 50, 90은 크게 차이가 나지 않고 모여있는 것을 알 수 있습니다.
gamma값이 30일 때 가장 효율이 좋았던 것을 알 수 있습니다.
여기서 주목할 점은 어느 정도 dimension이 확보되었을 때는(적어도 8차원 이상) 같은 training data에 같은 gamma 값이라면 dimension에 따른 차이가 그렇게 크지 않고 안정적이라는 것을 알 수 있었습니다.
즉 앞에 그림에서는 dimension에 따른 차이가 확연하게 드러난 반면, training data가 고정되고부터는 dimension의 차이가 크게 나지 않는 다는 것을 알 수 있습니다.
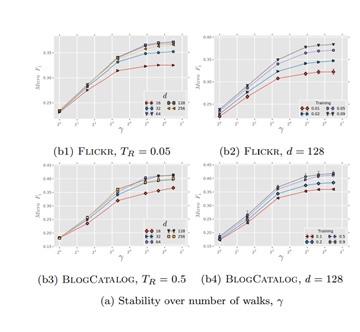
다음은 random walk 개수를 결정하는 감마 값이 x axis로 두고 진행한 실험입니다.
대체로 gamma 값이 클수록 성능이 올라갔지만 10개를 넘어가면서부터 성능 개선 효과가 미미해지는 것을 발견할 수 있습니다.
gamma 값이 크다는 것은 모델이 임베딩할 문장 에시가 많고, 어느 정도 비슷한 random walk가 많아진다는 의미로 epoch이 많아지면 수렴하는 것과 비슷한 원리라고 이해할 수 있습니다.
Conclusion 결론
본 논문을 정리하면 다음 세 가지로 요약할 수 있습니다.
1. 딥워크는 언어모델의 논리를 그래프에 적용해서 성공을 거두었으며
2. 큰 그래프 데이터에 대해서도 학습을 진행할 수 있었습니다.
3. 또한 모델의 여러 부분을 병렬적으로 학습을 진행해 효율적이고 빠른 학습이 가능합니다.
deep walk의 아쉬운 점은 randomwalk를 만들 때 weight를 고려하지 않고 정말 랜덤하게 이웃 노드를 방문했다는 점이었습니다.
이후 등장한 논문인 node2vec에서 이를 dfs와 bfs 기법을 사용해서 어느 정도 해소했다고 합니다.
'머신러닝,딥러닝 > WLT' 카테고리의 다른 글
| [추천 시스템 논문] SoReg : Social Regularization 논문 짧은 리뷰 (1) | 2023.01.31 |
|---|---|
| [추천시스템 논문] SoRec: Social Recommendataion using probilistic matrix factorization 리뷰 (0) | 2023.01.31 |